Python与Excel:分组
根据部门进行排序,然后按部门设置分组,核心代码是ws.row_dimensions.group(dept_rows[1], dept_rows[-1], outline_level=1)
outline_level 参数表示分组的级别,1 表示一级分组,2 表示二级分组,以此类推。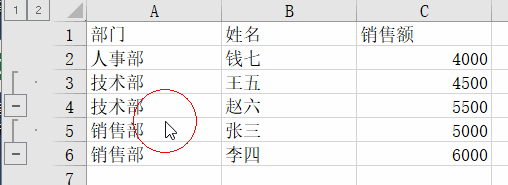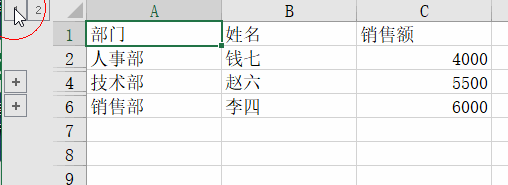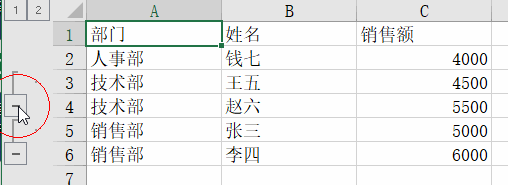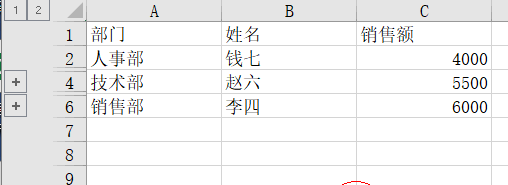
代码
python
import pandas as pd
from openpyxl import Workbook
# 示例数据
data = {
"部门": ["销售部", "销售部", "技术部", "技术部", "人事部"],
"姓名": ["张三", "李四", "王五", "赵六", "钱七"],
"销售额": [5000, 6000, 4500, 5500, 4000],
}
# 转换为 DataFrame 并按部门排序
df = pd.DataFrame(data)
df.sort_values("部门", inplace=True)
# 使用 openpyxl 创建分组
wb = Workbook()
ws = wb.active
# 写入表头
ws.append(["部门", "姓名", "销售额"])
# 收集所有数据行
all_data_rows = []
for _, row in df.iterrows():
all_data_rows.append([row["部门"], row["姓名"], row["销售额"]])
# 写入所有数据
for row_data in all_data_rows:
ws.append(row_data)
# 按部门设置分组
current_row = 2 # 数据从第 2 行开始
departments = df["部门"].unique()
for department in departments:
# 获取该部门的所有行号
dept_indices = df[df["部门"] == department].index.tolist()
dept_rows = [idx + 2 for idx in dept_indices] # 转换为Excel行号
# 为该部门设置分组(从第二行开始分组,第一行作为标题显示)
if len(dept_rows) > 1:
ws.row_dimensions.group(dept_rows[1], dept_rows[-1], outline_level=1)
# 调整列宽
ws.column_dimensions['A'].width = 15
ws.column_dimensions['B'].width = 15
ws.column_dimensions['C'].width = 15
# 保存文件
wb.save("pandas_分组数据.xlsx")