Python and Excel: Grouping
Sort by department, then group by department. The key code is:ws.row_dimensions.group(dept_rows[1], dept_rows[-1], outline_level=1)
The outline_level parameter shows the group level. 1 means first level group, 2 means second level group, and so on.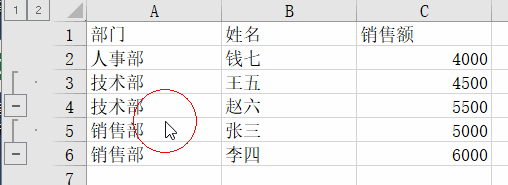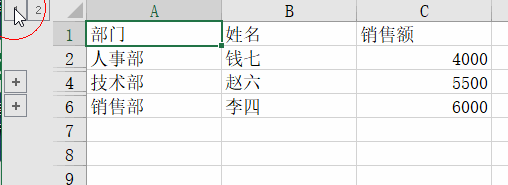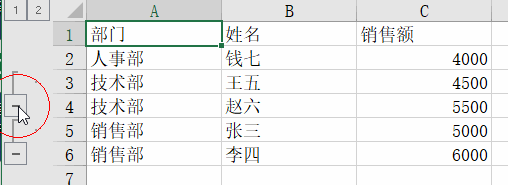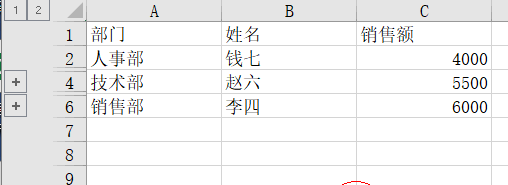
Code
python
import pandas as pd
from openpyxl import Workbook
# Sample data
data = {
"Department": ["Sales", "Sales", "Tech", "Tech", "HR"],
"Name": ["Zhang San", "Li Si", "Wang Wu", "Zhao Liu", "Qian Qi"],
"Sales": [5000, 6000, 4500, 5500, 4000],
}
# Convert to DataFrame and sort by department
df = pd.DataFrame(data)
df.sort_values("Department", inplace=True)
# Use openpyxl to create groups
wb = Workbook()
ws = wb.active
# Write header
ws.append(["Department", "Name", "Sales"])
# Collect all data rows
all_data_rows = []
for _, row in df.iterrows():
all_data_rows.append([row["Department"], row["Name"], row["Sales"]])
# Write all data
for row_data in all_data_rows:
ws.append(row_data)
# Set groups by department
current_row = 2 # Data starts from row 2
departments = df["Department"].unique()
for department in departments:
# Get all row numbers for this department
dept_indices = df[df["Department"] == department].index.tolist()
dept_rows = [idx + 2 for idx in dept_indices] # Convert to Excel row numbers
# Set group for this department (start grouping from row 2, show row 1 as header)
if len(dept_rows) > 1:
ws.row_dimensions.group(dept_rows[1], dept_rows[-1], outline_level=1)
# Adjust column widths
ws.column_dimensions['A'].width = 15
ws.column_dimensions['B'].width = 15
ws.column_dimensions['C'].width = 15
# Save file
wb.save("pandas_grouped_data.xlsx")